

This is inspired from the great site, Practical Cryptography which is a really good resource for code making and code breaking. One of their articles is about how we can use the Chi Squared test to crack a Caesar Shift code. Indeed, if you use an online program to crack a Caesar shift, they are probably using this technique (click to enlarge):

This is the formula that you will be using for Chi Squared. It looks more complicated than it is. Say we have the following message (also from Practical Cryptography):
AOLJHLZHYJPWOLYPZVULVMAOLLHYSPLZARUVDUHUKZPTWSLZAJPWOLY ZPAPZHAFWLVMZBIZAPABAPVUJPWOLYPUDOPJOLHJOSLAALYPUAOLWSH PUALEAPZZOPMALKHJLYAHPUUBTILYVMWSHJLZKVDUAOLHSWOHILA
We first work out the frequency of each letter which we do using the Counton site.

We next need to work out the expected values for each letter. To do this we first need the expected percentages for the English language:
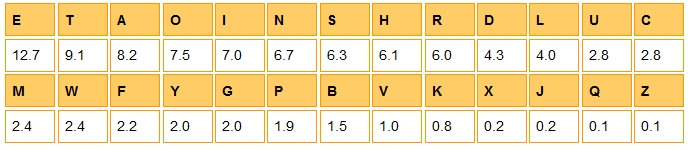
Then we can count the number of letters in the code we want to crack (162 – again we can use an online tool)
Now, to find the expected number of As in the code we simply do 162 x 0.082 = 13.284.
The actual number of As in the code is 18.
Therefore we can do (13.284-18)2/18 following the formula at the top of the page.
We then do exactly the same for the Bs in the code. The expected number is 162 x 0.015 = 2.43. The actual number is 3.
Therefore we can do (3-2.43)2 /2.43
We do this same method for all the letters A-Z and then add all those numbers together. This is our Chi Squared statistic. The lower the value, the closer the 2 distributions are. If the expected values and the observed values are the same then there will be a chi squared of zero.
If you add all the values together you get a Chi Squared value of ≈1634 – which is quite large! This is what we would expect – because we already know that the code we have received has letter frequencies quite different to normal English sentences. Now, what a Caesar Shift decoder can do is shift the received code through all the permutations and then for each one find out the Chi Squared value. The permutation with the lowest Chi Squared will be the solution.
For example, if we shift every letter in our received code back by one – using the Counton tool (so A goes to Z etc) we get:
ZNKIGKYGXIOVNKXOYUTKULZNKKGXROKYZQTUCTGTJYOSVRKYZIOVNKX YOZOYGZEVKULYAHYZOZAZOUTIOVNKXOTCNOINKGINRKZZKXOTZNKVRG OTZKDZOYYNOLZKJGIKXZGOTTASHKXULVRGIKYJUCTZNKGRVNGHKZ
We can then do the same Chi Squared calculations as before. This will give a Chi Squared of ≈3440 – which is an even worse fit than the last calculation. If we carried this on so that A goes to T we would get:
THECAESARCIPHERISONEOFTHEEARLIESTKNOWNANDSIMPLESTCIPHER SITISATYPEOFSUBSTITUTIONCIPHERINWHICHEACHLETTERINTHEPLA INTEXTISSHIFTEDACERTAINNUMBEROFPLACESDOWNTHEALPHABET
and a Chi Squared on this would show that this has a Chi Squared of ≈33 – ie it is a very good fit. (You will get closer to zero on very long code texts which follow standard English usage). Now, obviously we could see that this is the correct decryption without even working out the Chi Squared value – but this method allows a computer to do it, without needing the ability to understand English. Additionally a codebreaker who spoke no English would still be able to decipher this code, on mathematics alone.
The Practical Cryptography site have a tool for quickly working out Chi Squared values from texts – so you can experiment with your own codes. Note that this is a slightly different use of Chi-Squared as here we are not comparing with a critical value, but instead comparing all Chi Squared to find the lowest value.
